About
Home page of Steve Engledow.
Cat and human dad. Polygeek. Nihilistic optimist. Neutral good. NW on the political compass. Norwich, UK.
I work for AWS but this is where I keep non-work stuff.
Me in other places
Projects
I have a lot of half-finished crap on GitHub. This is a curated selection of the more finished, actually useful stuff.
Most of it is quite old at this point but still relevant.
Command line tools
Babel
https://github.com/stilvoid/babel
An easy-to-parse and easy-to-produce data exchange format for easing communication between processes written in different programming languages. There are definitely better choices for this now but I do have some ideas for a future iteration of this.
git-aux
https://github.com/stilvoid/git-aux
Allows you to use git to manage replicating your dotfiles between machines and that sort of thing.
git-cube
https://github.com/stilvoid/git-cube
Reminds you to commit before you exit a shell session.
git-get
https://github.com/stilvoid/git-get
A tool I still use every day.
Replaces git clone but organises repositories by their origin under ~/code.
maur
https://github.com/stilvoid/maur
A minimal tool for searching and installing packages from the AUR.
please
https://github.com/stilvoid/please
Please is a command line utility that makes it easy to integrate web APIs into your shell scripts.
PS1
https://github.com/stilvoid/ps1
My custom bash prompt with some nice features. I've been using this daily ever since I wrote it.
shue
https://github.com/stilvoid/shue
A command line tool for modifying and converting colour values for use with CSS etc.
Games
Lockdown
https://static.offend.me.uk/games/lockdown.html
Written for Ludum Dare 50 in 2022. Survive the zombie invasion...
Muze
https://static.offend.me.uk/games/muze.html
My entry for Black and White Jam in 2021. It's a simple maze game. Probably.
Santa's Skydive
https://static.offend.me.uk/games/santa-dive.html
My present to someone in a Secret Santa Jam.
Santa's sleigh has tipped over and dropped all the presents. Clearly, the only option is for Santa to skydive and gather them all back up.
Taaanks
https://static.offend.me.uk/games/taaanks.html
Heavily inspired by Scorched Tanks. This is my entry for LD 48.
Volver
https://static.offend.me.uk/games/volver.html
Spin the things to match the thing-holders.
Logoids
https://github.com/stilvoid/logoids
An Asteroids clone where you provide the Asteroid images.
Falsoyd
https://github.com/stilvoid/falsoyd
A terrible game I that wrote around 2000CE. tbh I don't know if it even compiles on modern systems.
Music
All my music is over on SoundCloud, for now.
Blog
An unorganised collection of things that I decided to write. Most of these are fairly old.
TBC
published 2024-08-28
In tidying up my corner of the interwebs, I put together a list of projects that I've worked on over the years. One of those is Falsoyd. I commented "I don't know if it even compiles on modern systems". Of course, that stuck in my head and inevitably I had to try...
Hoooo boy.
It has been a long time since I wrote anything in my once-favourite language, C (or C++). A GitHub search suggests it's been around 10 years. Fortunately, I had no intentions of really fixing any coding problems - just getting Falsoyd to run by brute force :D
It starts
git clone git@github.com:stilvoid/falysoyd
cd falsoyd
make
...
sdl-config: command not found
fatal error: 'SDL_mixer.h' file not found
Oh yeah, this was all SDL. Oh well, I'm sure that's still around!
brew install sdl
Warning: Formula sdl was renamed to sdl12-compat.
Ok well, it turns out SDL1.2 is looong deprecated but some kind person has written a compatibility library for SDL2 so that should all work quite nicely...
make
fatal error: 'SDL_mixer.h' file not found
brew install sdl_mixer
Error: sdl_mixer has been disabled because it is deprecated upstream! It was disabled on 2024-02-07.
If only I had tried this 6 months ago ;) After a quick look, SDL2_mixer seems to have the same API as in SDL1.2 so I'll nab the header file from there, include it in my CFLAGS, and link to SDL2_mixer in addition to the SDL1.2 (compat) library. What could possibly go wrong?!
make
...
src/map.h:35:6: error: cast from pointer to smaller type 'int' loses information
p.x=(int)x;
^~~~~~
src/map.h:36:6: error: cast from pointer to smaller type 'int' loses information
p.y=(int)y;
Ooh, an actual bug. Forgot to dereference some pointers. I wonder how that ever worked before. Well, it's an easy fix!
make
...
g++ src/world.o src/audio.o src/score.o src/bonus.o src/shot.o src/sprite.o src/ship.o src/alien.o src/main.o -o src/falsoyd `sdl-config --libs` -lSDL2_mixer
It compiled! That was unexpectedly easy. I was anticipating some nastiness with mixing SDL1.2 and SDL2_mixer.
(I glossed over a lot of compiler warnings in that "..." btw. Don't ignore your compiler warnings, folks!)
My fingers began to tremble (they didn't) as I nervously (I wasn't)
typed ./src/falsoyd...

It runs! I played it for a little while. Remembered how terrible it was and committed a branch with my changes. That'll do for now. Itch scratched.
Now I'm clearly going to have to make Falsoyd 2 in Löve, Pico-8, or Picotron ;)
Back to the Primitive
published 2024-07-23
I like text, plain text. Always have. But over the past several years (and it has been, as the kids say, a hot minute since I last blogged) I've found more and more bloat creeping into my daily life. I moved to a Mac Mini as my main machine about 4 years ago as I just gave up in the struggle between the way I think things ought to be and the "needs" of life working for a large corporate. In fairness, I have come to more or less enjoy MacOS but whenever I slip back into my Arch box with my i3 desktop, it feels so sleek.
Moving to the Mac has necessarily meant changing some of my regular workflow and tools. I don't know what it is about the Mac but it seemed to discourage me from being so heavily terminal-based as I was. I really can't put my finger on it. Regardless, I ended up moving from taking notes in markdown to Obsidian for a while and then eventually Logseq. Still just markdown files in a folder but the GUI is ever-present. I even found myself starting to use, and almost enjoy, VS Code!
Anyway, the point is, through Late Night Linux, I discovered Vimwiki and have started to love the terminal (and Vim) again. In fact, I started writing some code the other day and just automatically started it in Vim rather than VS Code. The rot is beginning to recede eh ;)
One of the tasks I decided to bring over to Vimwiki was maintaining my small and fairly pointless website. In another show of bloat, I had been through various markdown-to-website tools (ghost, hugo, jekyll), decided I disliked something about each one, and ended up rolling my own Python cruft. Inevitably, I came back to the site to make some changes after a few months and had completely forgotten how any of it was meant to work :) And that is what led me to the decision to try Vimwiki for the site as well as my note-taking.
The first challenge is that, while Vimwiki supports markdown syntax, it doesn't support it very well and requires more plugins to get it to spit out html. Over the years, my enthusiasm for markdown has waned considerably. I like the overall style of the markup but it's just too ambiguous and ends up causing more problems than it solves. So... the tool I want to use has it's own syntax and I'm not tied to my usual preference... obviously it's time to figure out how to convert all my existing posts ;)
I spent a nice afternoon discovering that pandoc is even more lovely than I had previously realised. Writing a new reader or writer for it is almost trivial. You write a lua file, create a few functions to parse/create text in various formats (e.g. emphasised, code blocks, bullet points), and then point pandoc at your lua file as if it were any other reader/writer option.
So here we are. This very infrequently updated blog is now written in vimwiki and I'm back to using the terminal and Vim on a daily basis like the last few years never happened.
Now to see what else I can over-enthusiastically convince myself should be a Wiki...
Maur - A minimal AUR helper
published 2019-11-13
This post is about the Arch User Repository. If you're not an Arch user, probably just move along ;)
There are lots of AUR helpers in existence already but, in the best traditions of open source, none of them work exactly how I want an AUR helper to work, so I created a new one.
Here it is: https://github.com/stilvoid/maur
maur (pronounced like "more") is tiny. At the time of writing, it's 49
lines of bash. It also has very few features.
Here is the list of features:
- Help text when you type
maur --helpormaur -h - A list of packages in the AUR when you type
maurwith no arguments - Help you install a package when you type
maur <package name>
The "help" when installing a package is this, and nothing more:
- Clone the package's AUR repository
- Open the
PKGBUILDin your default editor - Ask if you want to continue installing
- If you do, run
makepkg -si
If you think maur needs more features, use a different AUR helper.
If you find bugs, please submit an issue or, even better, a pull request.
Example usage
Searching the AUR
If you want to search for a package in the AUR, you can grep for it ;)
maur | grep maur
Installing a package
If you want to install a package, for example yay:
maur yay
Upgrading a package
Upgrade a package is the same as installing one. This will upgrade
maur:
maur maur
Using Git with AWS CodeCommit Across Multiple AWS Accounts
published 2019-02-12
(Cross-posted from the AWS DevOps blog)
I use AWS CodeCommit to host all of my private Git repositories. My repositories are split across several AWS accounts for different purposes: personal projects, internal projects at work, and customer projects.
The CodeCommit documentation shows you how to configure and clone a repository from one place, but in this blog post I want to share how I manage my Git configuration across multiple AWS accounts.
Background
First, I have profiles configured for each of my AWS environments. I connect to some of them using IAM user credentials and others by using cross-account roles.
I intentionally do not have any credentials associated with the default profile. That way I must always be sure I have selected a profile before I run any AWS CLI commands.
Here’s an anonymized copy of my ~/.aws/config file:
[profile personal]
region = eu-west-1
aws_access_key_id = AKIAIOSFODNN7EXAMPLE
aws_secret_access_key = wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
[profile work]
region = us-east-1
aws_access_key_id = AKIAIOSFODNN7EXAMPLE
aws_secret_access_key = wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
[profile customer]
region = eu-west-2
source_profile = work
role_arn = arn:aws:iam::123456789012:role/CrossAccountPowerUser
If I am doing some work in one of those accounts, I run
export AWS_PROFILE=work and use the AWS CLI as normal.
The problem
I use the Git credential helper so that the Git client works seamlessly with CodeCommit. However, because I use different profiles for different repositories, my use case is a little more complex than the average.
In general, to use the credential helper, all you need to do is place
the following options into your ~/.gitconfig file, like this:
[credential]
helper = !aws codecommit credential-helper $@
UserHttpPath = true
I could make this work across accounts by setting the appropriate value
for AWS_PROFILE before I use Git in a repository, but there is a much
neater way to deal with this situation using a feature released in Git
version
2.13,
conditional includes.
A solution
First, I separate my work into different folders. My ~/code/ directory
looks like this:
code
personal
repo1
repo2
work
repo3
repo4
customer
repo5
repo6
Using this layout, each folder that is directly underneath the code folder has different requirements in terms of configuration for use with CodeCommit.
Solving this has two parts; first, I create a .gitconfig file in each
of the three folder locations. The .gitconfig files contain any
customization (specifically, configuration for the credential helper)
that I want in place while I work on projects in those folders.
For example:
[user]
# Use a custom email address
email = sengledo@amazon.co.uk
[credential]
# Note the use of the --profile switch
helper = !aws --profile work codecommit credential-helper $@
UseHttpPath = true
I also make sure to specify the AWS CLI profile to use in the
.gitconfig file which means that, when I am working in the folder, I
don’t need to set AWS_PROFILE before I run git push, etc.
Secondly, to make use of these folder-level .gitconfig files, I need to
reference them in my global Git configuration at ~/.gitconfig
This is done through the includeIf section. For example:
[includeIf "gitdir:~/code/personal/"]
path = ~/code/personal/.gitconfig
This example specifies that if I am working with a Git repository that
is located anywhere under ~/code/personal/, Git should load additional
configuration from ~/code/personal/.gitconfig. That additional file
specifies the appropriate credential helper invocation with the
corresponding AWS CLI profile selected as detailed earlier.
The contents of the new file are treated as if they are inserted into
the main .gitconfig file at the location of the includeIf section.
This means that the included configuration will only override any
configuration specified earlier in the
config.
git-get
published 2018-11-08
Because I work on a lot of different projects spread across a lot of accounts at multiple git hosting providers, I try to keep my code folder in some semblance of order by having subfolders for things.
A while ago, I decided to make things even simpler by letting the git repos I was cloning dictate where they should live. I took inspiration from the way go expects you to organise your code.
Today, I decided to apply the three virtues and wrote some code to handle this for me.
Introducing git-get
git-get is an opinionated git command that helps you keep your code folder in order.
You use git-get as a replacement for git clone and it will decide
where your code should live :)
git get https://github.com/stilvoid/git-get
Cloning into '/home/steve/code/github.com/stilvoid/git-get'...
Laziness is the primary virtue.
Heroes: Building some old code
published 2018-08-14
For the end result of this post, see my AUR package of Heroes.
The other day, something reminded me of a game I used to really enjoy playing back in my early days of getting to know Linux. That game was Heroes. It's a clone of Snake/Tron/Nibbles but with some fun additions, a nice graphical style, and some funky visual effects.

So, of course, I immediately decided to install it.
$ pacman -Ss heroes
No results. Nothing in the AUR either. There is only one other course of action: I'm going to create an AUR package for it!
It looks like the last change to the game was 16 years ago so it could be fun getting it to compile with a modern toolchain.
Getting Heroes to compile in 2018
I put together a basic PKGBUILD that pulls down the source and data files from the Heroes sourceforge page and then runs:
./configure
make
Here's the first of what I'm sure are many failure messages:
hedlite.c:48:20: error: static declaration of ‘tile_set_img’ follows non-static declaration
static a_pcx_image tile_set_img;
^~~~~~~~~~~~
In file included from hedlite.c:44:
const.h:52:20: note: previous declaration of ‘tile_set_img’ was here
extern a_pcx_image tile_set_img, font_deck_img;
^~~~~~~~~~~~
Some forewarning: it's been quite some time since I wrote anything serious in C and I was never an expert in it anyway. But I think I know enough to fix this and so just commented out the static declaration as, after poking around in the code a bit, it doesn't seem like it's necessary anyway.
Now the compilation succeeds but I get the following error during linking:
/usr/bin/ld: camera.o: undefined reference to symbol 'sin@@GLIBC_2.2.5'
/usr/bin/ld: /usr/lib/libm.so.6: error adding symbols: DSO missing from command line
Turns out that for some reason, the developers forgot to include the math<small>(s)</small> library. I'm guessing that perhaps it used to be linked by default in a previous version of GCC.
LDFLAGS=-lm ./configure
make
Now it at least compiles correctly! Next up, compiling the data, music, and sound effects packages.
Amazingly, those all worked correctly and I was able to play the game!
However, this game was written a while ago and originally targeted MS-DOS so it has a window size of 320x200 which looks rather ridiculous on my 1920x1080 desktop ;)
So I set about trying to set the default screen mode so that the game starts in full screen...
Fortunately, it looks like this is relatively easy. I just modified a
few variables and changed a command line flag from -F | --full-screen
to -W | --windowed.
Next up, rather than rely on SDL's built-in
scaling (it looks blurry and weird), I need to enable Heroes' quadruple
flag -4 by default. In fact, I removed all the scaling options and
just left it to default to scaling 4-fold as that leaves the game with a
resolution of 1280x800 which seems a reasonable default these days. I'm
sure I'll receive bug reports if it's not ;)
The very last thing I've done is to enable the high quality mixer by default and remove the command line option from the game. CPU is a little more abundant now than it was in 2002 ;)
Submitting the AUR package
Things have changed since I last submitted a package to the AUR so here's a brief writeup - if only to remind myself in future ;)
First step was to update the SSH key in my AUR account as it contained a key from my old machine.
Next up, I added a remote to my repository:
$ git remote add aur ssh://aur@aur.archlinux.org/heroes.git
$ git fetch aur # This step causes AUR to create a record for the package
The next step is to generate AUR's .SRCINFO file and rebase it into
every commit (AUR requires this).
$ git filter-branch --tree-filter "makepkg --printsrcinfo > .SRCINFO"
And then push it to the AUR repository:
$ git push -u aur master
Testing it out
I use packer to make using AUR easier I'm lazy).
$ packer -S heroes
SUCCESS!
All in all, this wasn't anywhere near as painful as I'd expected. Time to play some Heroes :D
Shue
published 2018-06-03
I finally got around to releasing a tool I wrote a while back (git says I started it in November 2015).
It's called Shue and you can find it on github.
If you dig back in the commit history, you'll see that Shue was originally intended as a tool for converting rgb colour values into their nearest equivalent bash colour codes.
Shue doesn't do that now as I haven't really needed anything that does it since that one time :) I might bring back that functionality at some point but for now, here's what Shue does do:
- Converts colour representations between various rgb formats: 6-digit
hex (e.g.
#ff9900), 3-digit hex (e.g.#f90), and CSS-style RGB values (e.g.rgb(255, 153, 0). - Perform a few basic operations on colours before converting to the
various representations:
- Invert
- Darken
- Lighten
I wrote this at the time because I was fiddling with a few websites and frequently needed the above functionality.
It's written in Go and there are binaries for Linux, Mac, and Windows on the releases page.
Let me know if you find it useful.
An evening of linux on the desktop
published 2017-07-10
Last time, I wrote about trying a few desktop environments to see what's out there, keep things fresh, and keep me from complacency. Well, as with desktop environments, so with text editors. I decided briefly that I would try a few of the more recent code editors that are around these days. Lured in by their pleasing, modern visuals and their promises of a smooth, integrated experience, I've been meaning to give these a go for a while. Needless to say, as a long-time vim user, I just found myself frustrated that I wasn't able to get things done as efficiently in any of those editors as I could in vim ;) I tried installing vim keybindings in Atom but it just wasn't the same as a very limited set of functionality was there. As for the integrated environment, when you have tmux running by default, everything's integrated anyway.
And, as with editors, so once again with desktop environments. I've decided to retract my previous hasty promise and no longer to bother with trying any other environments; i3 is more than fine :)
However, I did spend some time this evening making things a bit prettier so here are some delicious configs for posterity:
Configs
Xresources
I've switched back to xterm from urxvt because, er... dunno.
Anyway, I set some nice colours for terminals and some magic stuff that makes man pages all colourful :)
XTerm*faceName: xft:Hack:regular:size=12
*termName: xterm-256color
! Colourful man pages
*VT100.colorBDMode: true
*VT100.colorBD: cyan
*VT100.colorULMode: true
*VT100.colorUL: darkcyan
*VT100.colorITMode: true
*VT100.colorIT: yellow
*VT100.veryBoldColors: 518
! terminal colours
*foreground:#CCCCCC
*background:#2B2D2E
!black darkgray
*color0: #2B2D2E
*color8: #808080
!darkred red
*color1: #FF0044
*color9: #F92672
!darkgreen green
*color2: #82B414
*color10: #A6E22E
!darkyellow yellow
*color3: #FD971F
*color11: #E6DB74
!darkblue blue
*color4: #266C98
*color12: #7070F0
!darkmagenta magenta
*color5: #AC0CB1
*color13: #D63AE1
!darkcyan cyan
*color6: #AE81FF
*color14: #66D9EF
!gray white
*color7: #CCCCCC
*color15: #F8F8F2
Vimrc
Nothing exciting here except for discovering a few options I hadn't previous known about:
" Show a marker at the 80th column to encourage nice code
set colorcolumn=80
highlight ColorColumn ctermbg=darkblue
" Scroll the text when we're 3 lines from the top or bottom
set so=3
" Use browser-style incremental search
set incsearch
" Override the default background colour in xoria256 to match the terminal background
highlight Normal ctermbg=black
" I like this theme
colorscheme xoria256
i3
I made a few colour tweaks to my i3 config so I get colours that match my new Xresources. One day, I might see if it's easy enough to have them both read colour definitions from the same place so I don't have to define things twice.
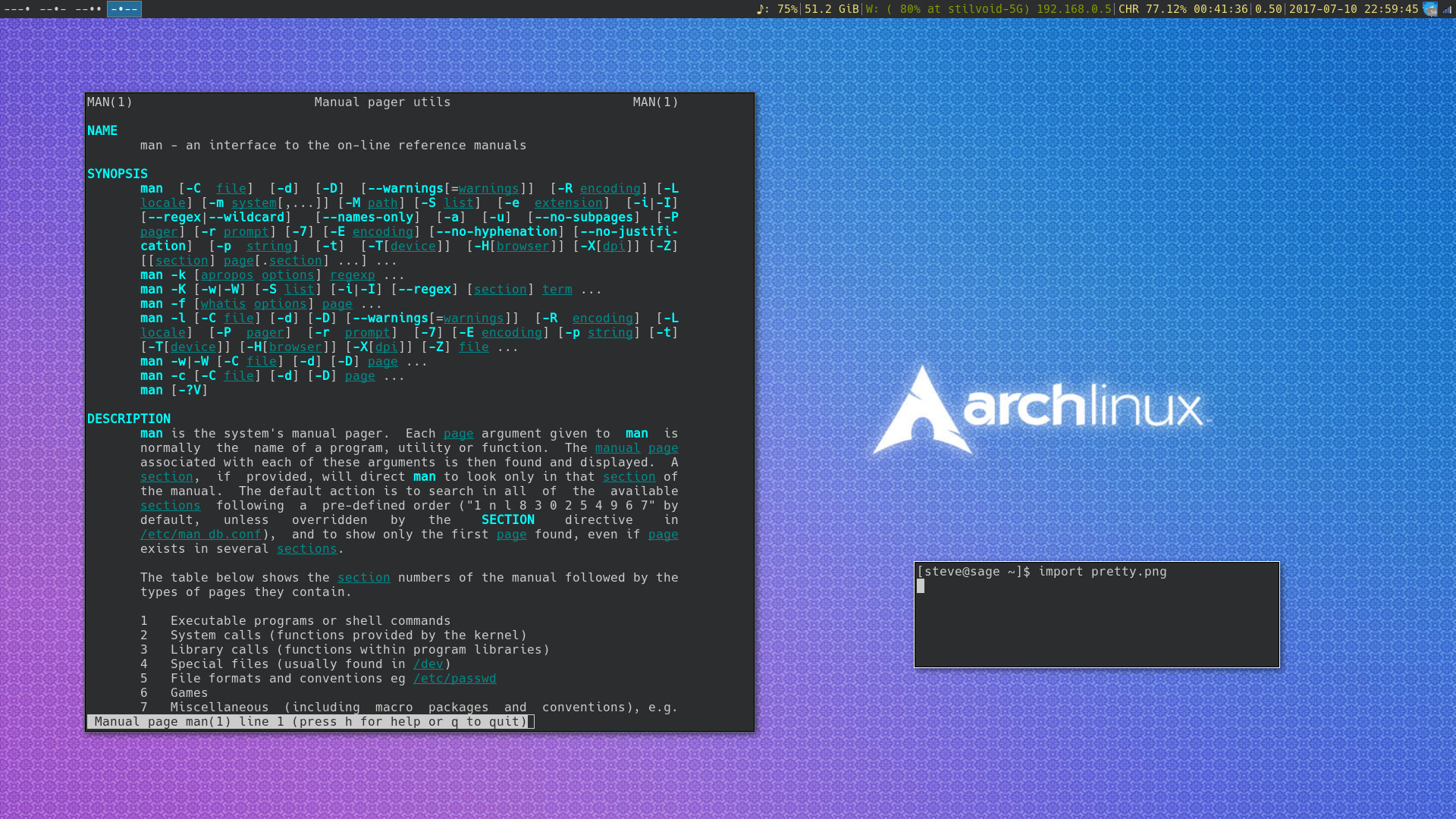
The result
Here's what it looks like:
The day of linux on the desktop
published 2017-06-15
It’s been a while since I last tried out a different desktop environment on my laptop and I’ve been using i3 for some time now so it’s only fair to give other things a go ;)
To test these out, I ran another X display - keeping my original one
running so I could switch back and forth to take notes - and started
each environment with DISPLAY=:1 <the command to start the desktop>.
I’ll start with just one today and perhaps review some others another time.
Deepin
In summary: bits of Gnome Shell, Chrome OS, and Mac OSX but not quite as polished as any of them.
The Deepin Desktop Environment (DDE - from the Deepin
distribution) installed easily
enough under Arch with a quick pacman -S deepin deepin-extra. It also
started up easily with an unambiguous startdde.
Immediately on startup, DDE plays a slightly annoying chime presumably just to remind you of how far we’ve come since Windows 95. The initial view of the desktop looks similar to OSX or Chrome OS with file icons on the desktop and a launcher bar centred across the bottom of the screen.
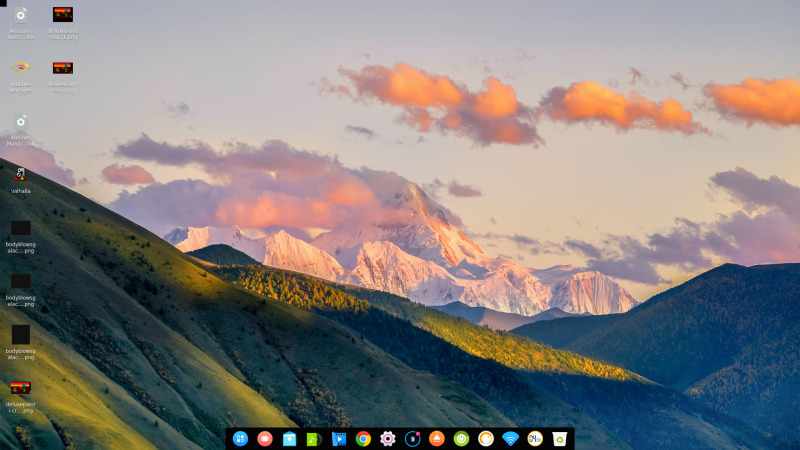
The first thing I tried was clicking on a button labelled Quoted only to be presented with a prompt telling me Quoted and an OK button. So far, so enigmatic. So then I tried a trusty right-click on the desktop which brought up the expected context menu. In the menu was a Quoted option so I plumped for that, thinking that perhaps that was where I could enable the mystic Quoted. Clicking the Quoted button opened a dark-themed panel from the right-hand side, similar to the information panel you get in OSX. I searched through that panel for a good couple of minutes but could find no allusion to any Quoted.
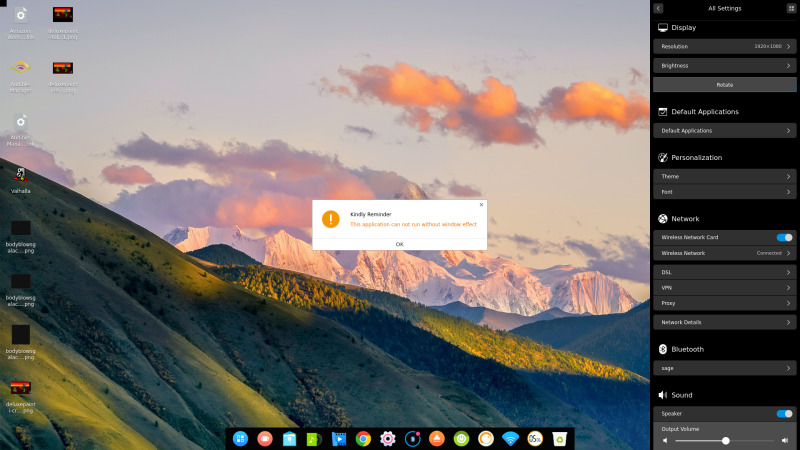
Unperturbed, I decided to press on and see what other features Deepin had to offer…
Moving the mouse around the desktop a bit, I discovered that Deepin has borrowed some ideas from Gnome shell as well as OSX and Chrome OS. Moving the mouse pointer into the top-left corner of the screen brings up an application list similar to Gnome’s launcher. The bottom-right corner reveals the settings panel. The top-right does nothing and the bottom-left, wonder of wonders, brings up my old favourite, the Quoted.
I poked around in the settings a bit more but didn’t really see anything
of interest so I fired up what looks to be the last part of Deepin left
for me to explore: the file manager. It does the job and it’s not very
interesting although I did discover that Deepin also has it’s own
terminal emulator (unsurprisingly called deepin-terminal) which has a
snazzy Matrix theme to it
but is otherwise uninteresting.
That’s it, I’m bored. Next!
I tried Budgie and LXQT for a few minutes each at this point but they weren’t immediately interesting enough to make me want to write about them just now :)
Digital Subscriber
published 2016-02-25
Maybe it’s just me, but I reckon DSLs are the next (ok ok, they’ve been around for ages) big (ok, hipster) thing. I know I’m by no means the first to say so it’s just that I’m increasingly bemused at seeing things squeezed into data structures they’ve outgrown.
In general, as everyone’s finally warming to the idea that you can use code to describe not just your application but also how it’s deployed, we’re reaching a state where that code needs to be newbie-friendly - by which I mean that it ought to be easily understandable by humans. If it isn’t, it’s prone to mistakes.
A few months ago, I experimented with creating a DSL for writing web pages and I was fairly happy with the result (though there’s lots more work to be done). I’m thinking of applying the same ideas to CloudFormation.
resources:
db:
type: rds
engine: mysql
size: c3.xlarge
app:
type: ec2
ami: my-app-image
size: t2.micro
scale:
min: 1
max: 10
expose: 80
security:
db: app
app: 0.0.0.0:80
Obviously I’ve put little to no thought into the above but it shouldn’t be too hard to come up with something useful.
Maybe some day soon ;)
Ford
published 2015-12-14
Today I become a Firefox add-on developer!
Really, it was far too easy and a little disappointing that I needed to bother, as all I needed was a simple way to hide the browser chrome when I wanted a little more screen space for the content or I wanted a distraction-free environment for reading an article.
I wrote Focus Mode for Firefox to do just that :)
Now, someone tell me why that’s not already a standard feature in Firefox. Or even better, tell me that it is and that I just failed to notice it. And while you’re at it, tell me why I couldn’t find an existing extension that does it!
Sorted
published 2015-11-30
I decided to restructure the folder I keep code in (~/code, natch) -
taking my cue from how Go does it -
so that the folder structure represents where code has come from.
As with all things, moving a couple of hundred folders by hand seemed far too daunting so I wrote a bash script to do it.
This script enters each subdirectory within the current directory and, if it has a git remote, moves it to a folder that represents the git remote’s path.
For example, if I had a folder called scripts that had a git remote of
git@github.com/stilvoid/utils.git, this script will move the folder to
github.com/stilvoid/utils.
#!/bin/bash
# Target directory for renamed folders
BASE=/home/steve/code/sorted
for i in $(find ./ -maxdepth 1 -mindepth 1 -type d); do
cd "$i"
folder="$(git remote -v 2>/dev/null | head -n 1 | awk '{print $2}' | sed -e 's/^.*:\/\///' | sed -e 's/:/\//' | sed -e 's/^.*@//' | sed -e 's/\.git$//')"
cd ..
if [ -n "$folder" ]; then
mkdir -p "$BASE/$(dirname $folder)"
mv "$i" "$BASE/$folder"
fi
done
Yes it’s horrid but it did today’s job ;)
Twofer
published 2015-09-17
After toying with the idea for some time, I decided I’d try setting up 2FA on my laptop. As usual, the arch wiki had a nicely written article on setting up 2FA with the PAM module for Google Authenticator.
I followed the instructions for setting up 2FA for ssh and that worked
seamlessly so I decided I’d then go the whole hog and enable the module
in /etc/pam.d/system-auth which would mean I’d need it any time I had
to login at all.
Adding the line:
auth sufficient pam_google_authenticator.so
had the expected effect that I could login with just the verification
code but that seems to defeat the point a little so I bit my lip and
changed sufficient to required which would mean I’d need my password
and the code on login.
I switched to another VT and went for it. It worked!
So then I rebooted.
And I couldn’t log in.
After a couple of minutes to download an ISO to boot from using another
machine, putting it on a USB stick, booting from it, and editing my
system-auth file, I realised why:
auth required pam_google_authenticator.so
auth required pam_unix.so try_first_pass nullok
auth required pam_ecryptfs.so unwrap
My home partition is encrypted and so the Google authenticator module obviously couldn’t load my secret file until I’d already logged in.

I tried moving the pam_google_authenticator.so line to the bottom of
the auth group but that didn’t work either.
How could this possibly go wrong...
So, the solution I came up with was to put the 2fa module into the
session group. My understanding is that this will mean PAM will ask me
to supply a verification code once per session which is fine by me; I
don’t want to have to put a code in every time I sudo anyway.
My question is, will my minor abuse of PAM bite me in the arse at any point? It seems to do what I expected, even if I log in through GDM.
Here’s my current system-auth file:
#%PAM-1.0
auth required pam_unix.so try_first_pass nullok
auth required pam_ecryptfs.so unwrap
auth optional pam_permit.so
auth required pam_env.so
account required pam_unix.so
account optional pam_permit.so
account required pam_time.so
password optional pam_ecryptfs.so
password required pam_unix.so try_first_pass nullok sha512 shadow
password optional pam_permit.so
session required pam_limits.so
session required pam_unix.so
session optional pam_ecryptfs.so unwrap
session optional pam_permit.so
session required pam_google_authenticator.so
Pretty please
published 2015-06-22
I’ve been making a thing to solve some problems I always face while building web APIs. Curl is lovely but it’s a bit too flexible.
Also, web services generally spit out one of a fairly common set of formats: (json, xml, html) and I often just want to grab a value from the response and use it in a script - maybe to make the next call in a workflow.
So I made please which makes it super simple to do things like making a web request and grabbing a particular value from the response.
For example, here’s how you’d get the page title from this site:
please get https://engledow.me/ | please parse html.head.title.#text
Or getting a value out of the json returned by jsontest.com’s IP address API:
please get http://ip.jsontest.com/ | please parse ip
The parse part of please is the most fun; it can convert between a
few different formats. Something I do quite often is grabbing a json
response from an API and spitting it out as yaml so I can read it
easily. For example:
please get http://date.jsontest.com/ | please parse -o yaml
(alright so that’s a poor example but the difference is huge when it’s a complicated bit of json)
Also handy for turning an unreadable mess of xml into yaml (I love yaml for its readability):
echo '<docroot type="messydoc"><a><b dir="up">A tree</b><b dir="down">The ground</b></a></docroot>' | please parse -o yaml
As an example, of the kinds of things you can play with, I made a tool for generating graphs from json.
I’m still working on please; there will be bugs; let me know about
them.
Andy and Teddy are waving goodbye
published 2015-05-15
Most of the time, when I've got some software I want to write, I do it in python or sometimes bash. Occasionally though, I like to slip into something with a few more brackets. I've written a bit of C in the past and love it but recently I've been learning Go and what’s really struck me is how clever it is. I’m not just talking about the technical merits of the language itself; it’s clever in several areas:
- You don’t need to install anything to run Go binaries.
At first - I’m sure like many others - I felt a little revulsion when I heard that Go compiles to statically-linked binaries but after having used and played with Go a bit over the past few weeks, I think it’s rather clever and was somewhat ahead of the game. In the current climate where DevOps folks (and developers) are getting excited about containers and componentised services, being able to simply curl a binary and have it usable in your container without needing to install a stack of dependencies is actually pretty powerful. It seems there’s a general trend towards preferring readiness of use over efficiency of space used both in RAM and disk space. And it makes sense; storage is cheap these days. A 10MiB binary is no concern - even if you need several of them - when you have a 1TiB drive. The extravagance of large binaries is no longer so relevant when you’re comparing it with your collection of 2GiB bluray rips. The days of needing to count the bytes are gone.
- Go has the feeling of C but without all that tedious mucking about in <del>hyperspace</del> memory
Sometimes you just feel you need to write something fairly low level and you want more direct control than you have whilst you’re working from the comfort blanket of python or ruby. Go gives you the ability to have well-defined data structures and to care about how much memory you’re eating when you know your application needs to process tebibytes of data. What Go doesn't give you is the freedom to muck about in memory, fall off the end of arrays, leave pointers dangling around all over the place, and generally make tiny, tiny mistakes that take years for anyone to discover.
- The build system is designed around how we (as developers) use code hosting facilities
Go has a fairly impressive set of features built in but if you need something that’s not already included, there’s a good chance that someone out there has written what you need. Go provides a package search tool that makes it very easy to find what you’re looking for. And when you've found it, using it is stupidly simple. You add an import declaration in your code:
import "github.com/codegangsta/cli"
which makes it very clear where the code has come from and where you’d need to go to check the source code and/or documentation. Next, pulling the code down and compiling it ready for linking into your own binary takes a simple:
go get github.com/codegangsta/cli
Go implicitly understands git and the various methods of retrieving code so you just need to tell it where to look and it’ll figure the rest out.
In summary, I’m starting to wonder if Google have a time machine. Go seems to have nicely predicted several worries and trends since its announcement: Docker, Heartbleed, and social coding.
Building a componentised application
published 2015-05-14
Most of what’s here is hardly new ground but I felt it worth noting down the current strategy we’re using to develop and build what we’re working on at Proxama.
Without going into any of the details, it’s a web application with a front end written using Ember and various services that it calls out to, written using whatever seems appropriate per service.
At the outset of the project, we decided we would bite the bullet and build for Docker from the outset. This meant we would get to avoid the usual dependency and developer environment setup nightmares.
The problem
What we quickly realised as we started to put the bare bones of a few of the services in place, was that we had three seemingly conflicting goals for each component and for the application as a whole.
- Build images that can be deployed in production.
- Allow developers to run services locally.
- Provide a means for running unit tests (both by developers and our CI server).
So here’s what we've ended up with:
The solution
Or: docker-compose to the rescue
Folder structure
Here’s what the project layout looks like:
Project
|
+-docker-compose.yml
|
+-Service 1
| |
| +-Dockerfile
| |
| +-docker.compose.yml
| |
| +-<other files>
|
+-Service 2
|
|
+-Dockerfile
|
+-docker.compose.yml
|
+-<other files>
Building for production
This is the easy bit and is where we started first. The Dockerfile for
each service was designed to run everything with the defaults. Usually,
this is something simple like:
FROM python:3-onbuild
CMD ["python", "main.py"]
Our CI server can easily take these, produce images, and push them to the registry.
Allowing developers to run services locally
This is slightly harder. In general, each service wants to do something
slightly different when being run for development; e.g. automatically
restarting when code changes. Additionally, we don’t want to have to
rebuild an image every time we make a code change. This is where
docker-compose comes in handy.
The docker-compose.yml at the root of the project folder looks like
this:
service1:
build: Service 1
environment:
ENV: dev
volumes:
- Service 1:/usr/src/app
links:
- service2
- db
ports:
- 8001:8000
service2:
build: Service2
environment:
ENV: dev
volumes:
- Service 2:/usr/src/app
links:
- service1
- db
ports:
- 8002:8000
db:
image: mongo
This gives us several features right away:
- We can locally run all of the services together with
docker-compose up
- The
ENVenvironment variable is set todevin each service so that the service can configure itself when it starts to run things in "dev" mode where needed.
- The source folder for each service is mounted inside the container. This means you don’t need to rebuild the image to try out new code.
- Each service is bound to a different port so you can connect to each part directly where needed.
- Each service defines links to the other services it needs.
Running the tests
This was the trickiest part to get right. Some services have dependencies on other things even just to get unit tests running. For example, Eve is a huge pain to get running with a fake database so it’s much easier to just link it to a temporary "real" database.
Additionally, we didn't want to mess with the idea that the images
should run production services by default but also didn’t want to
require folks to need to churn out complicated docker invocations like
docker run --rm -v $(pwd):/usr/src/app --link db:db service1 python -m unittest
just to run the test suite after coding up some new features.
So, it was docker-compose to the rescue again :)
Each service has a docker-compose.yml that looks something like:
tests:
build: .
command: python -m unittest
volumes:
- .:/usr/src/app
links:
- db
db:
image: mongo
Which sets up any dependencies needed just for the tests, mounts the local source in the container, and runs the desired command for running the tests.
So, a developer (or the CI box) can run the unit tests with:
docker-compose run tests
Summary
- Each
Dockerfilebuilds an image that can go straight into production without further configuration required.
- Each image runs in "developer mode" if the
ENVenvironment variable is set.
- Running
docker-compose upfrom the root of the project gets you a full stack running locally in developer mode.
- Running
docker-compose run testsin each service’s own folder will run the unit tests for that service - starting any dependencies as needed.
Why-fi?
published 2015-04-29
I’m an arch linux user and I love it; there’s no other distro for me. The things that arch gets criticism for are the exact same reasons I love it and they all more or less boil down to one thing: arch does not hold your hand.
It’s been a while since an update in arch caused me any problems but it did today.
It seems there’s an
issue with the
latest version of wpa_supplicant which renders it incompatible with
the way wifi is setup at boot time. The problem was caught and resolved
very quickly by package maintainers who simply rolled the
wpa_supplicant package back. However, I was unlucky enough to have
caught the intervening upgrade shortly before turning my laptop off. I
came home this evening to find I had no wifi!
This wasn't a huge challenge but I haven’t written a blog post for a while and someone might find this useful:
If your wifi doesn't start at boot…
And you’re using a laptop with no ethernet port…
And you know an upgrade will solve your problem…
How do you get internet so you can upgrade?
Simples :)
The steps
First, find the name of your wireless interface:
iw dev
Which will output something like:
phy#0
Interface wlp2s0
ifindex 2
wdev 0x1
addr e8:b1:fc:6c:bf:b5
type managed
channel 11 (2462 MHz), width: 20 MHz, center1: 2462 MHz
Where wlp2s0 is the bit we’re interested in.
Now bring the interface up:
ip link set wlp2s0 up
Connect to the access point:
iw dev wlp2s0 connect "AP name"
Create a temporary configuration file for wpa_supplicant:
wpa_passphrase "AP name" "password" > /tmp/wpa.config
Run wpa_supplicant to authenticate with the access point:
wpa_supplication -iwlp2s0 -c/tmp/wpa.config
In another terminal (or you could have backgrounded the above), run
dhcpcd to get an IP address from your router:
dhcpcd wlp2s0
Update and reboot or whatever :)
Cleaning out my closet
published 2015-03-12
Or: Finding out what crud you installed that’s eating all of your space in Arch Linux
I started running out of space on one of my Arch boxes and wondered (beyond what was in my home directory) what I’d installed that was eating up all the space.
A little bit of bash-fu does the job:
for pkg in $(pacman -Qq); do
size=$(pacman -Qi $pkg | grep "Installed Size" | cut -d ":" -f 2)
echo "$size | $pkg"
done | sed -e 's/ //g' | sort -h
This outputs a list of packages with those using the most disk space at the bottom:
25.99MiB|llvm-libs
31.68MiB|raspberrypi-firmware-examples
32.69MiB|systemd
32.86MiB|glibc
41.88MiB|perl
54.31MiB|gtk2
62.13MiB|python2
73.27MiB|gcc
77.93MiB|python
84.21MiB|linux-firmware
The above is from my pi; not much I can uninstall there ;)
Keychain and GnuPG >= 2.1
published 2015-01-02
A while ago, I started using keychain
to manage my ssh and gpg agents. I did this with the following in my
.bashrc
# Start ssh-agent
eval $(keychain --quiet --eval id_rsa)
Recently, arch updated gpg to version
2.1.1 which, as per the
announcement, no
longer requires the GPG_AGENT_INFO environment variable.
Unfortunately, tools like keychain don’t know about that and still expect it to be set, leading to some annoying breakage.
My fix is a quick and dirty one; I appended the following to .bashrc
export GPG_AGENT_INFO=~/.gnupg/S.gpg-agent:$(pidof gpg-agent):1
:)
Testing a Django app with Docker
published 2014-12-09
I've been playing around with Docker a fair bit and recently hit upon a configuration that works nicely for me when testing code at work.
The basic premise is that I run a docker container that pretty well emulates the exact environment that the code will run in down to the OS so I don’t need to care that I’m not running the same distribution as the servers we deploy to and that I can test my code at any time without having to rebuild the docker image.
Here’s an annotated Dockerfile with the project-specific details removed.
# We start with ubuntu 14.04
FROM ubuntu:14.04
MAINTAINER Steve Engledow <steve@engledow.me>
USER root
# Install OS packages
# This list of packages is what gets installed by default
# on Amazon's Ubuntu 14.04 AMI plus python-virtualenv
RUN apt-get update \
&& apt-get -y install software-properties-common git \
ssh python-dev python-virtualenv libmysqlclient-dev \
libqrencode-dev swig libssl-dev curl screen
# Configure custom apt repositories
# and install project-specific packages
COPY apt-key.list apt-repo.list apt.list /tmp/
# Not as nice as this could be as docker defaults to sh rather than bash
RUN while read key; do curl --silent "$key" | apt-key add -; done < /tmp/apt-key.list
RUN while read repo; do add-apt-repository -y "$repo"; done < /tmp/apt-repo.list
RUN apt-get -qq update
RUN while read package; do apt-get -qq -y install "$package"; done < /tmp/apt.list
# Now we create a normal user and switch to it
RUN useradd -s /bin/bash -m ubuntu \
&& chown -R ubuntu:ubuntu /home/ubuntu \
&& passwd -d ubuntu
USER ubuntu
WORKDIR /home/ubuntu
ENV HOME /home/ubuntu
# Set up a virtualenv andinstall python packages
# from the requirements file
COPY requirements.txt /tmp/
RUN mkdir .myenv \
&& virtualenv -p /usr/bin/python2.7 ~/.myenv \
&& . ~/.myenv/bin/activate \
&& pip install -r /tmp/requirements.txt \
# Set PYTHONPATH and activate the virtualenv in .bashrc
RUN echo "export PYTHONPATH=~/myapp/src" > .bashrc \
&& echo ". ~/.myenv/bin/activate" >> .bashrc
# Copy the entrypoint script
COPY entrypoint.sh /home/ubuntu/
EXPOSE 8000
ENTRYPOINT ["/bin/bash", "entrypoint.sh"]
And here’s the entrypoint script that nicely wraps up running the django application:
#!/bin/bash
. ./.bashrc
cd myapp/src
./manage.py $*
You generate the base docker image from these files with
docker build -t myapp ./.
Then, when you’re ready to run a test suite, you need the following invocation:
docker run -ti --rm -P -v ~/code/myapp:/home/ubuntu/myapp myapp test
This mounts ~/code/myapp and /home/ubuntu/myapp within the Docker
container meaning that you’re running the exact code that you’re working
on from inside the container :)
I have an alias that expands that for me so I only need to type
docked myapp test.
Obviously, you can substitute test for runserver, syncdb or
whatever :)
This is all a bit rough and ready but it’s working very well for me now and is repeatable enough that I can use more-or-less the same script for a number of different django projects.
Just call me Anneka
published 2014-12-01
I had an idea a few days ago to create a Pebble watchface that works like an advent calendar; you get a new christmas-themed picture every day.
Here it is :) was:
https://apps.pebble.com/applications/547bad0ffb079735da00007c
> Update 2024: Pebble is long gone and so is the site that hosted my watchfaces :(
The fun part however, was that I completely forgot about the idea until today. Family life and my weekly squash commitment meant that I didn't have a chance to start work on it until around 22:00 and I really wanted to get it into the Pebble store by midnight (in time for the 1st of December).
I submitted the first release at 23:55!
Enjoy :)
I’ll put the source on GitHub soon. Before that, it’s time for some sleep.
tmux
published 2014-06-17
tmux is the best thing ever. That is all.
No, that is not all. Here is how I make use of tmux to make my life measurably more awesome:
First, my .tmux.conf. This changes tmux’s ctrl-b magic key binding
to ctrl-a as I’ve grown far too used to hitting that from when I used
screen. I set up a few other
screen-like bindings too. Finally, I set a few options that make tmux
work better with urxvt.
# Set the prefix to ^A.
unbind C-b
set -g prefix ^A
bind a send-prefix
# Bind c to new-window
unbind c
bind c new-window -c $PWD
# Bind space, n to next-window
unbind " "
bind " " next-window
unbind n
bind n next-window
# Bind p to previous-window
unbind p
bind p previous-window
# A few other settings to make things funky
set -g status off
set -g aggressive-resize on
set -g mode-keys vi
set -g default-terminal screen-256color
set -g terminal-overrides 'rxvt-unicode*:sitm@'
And then here’s what I have near the top of my .bashrc:
# If tmux isn't already running, run it
[ -z "$TMUX" ] && exec ~/bin/tmux
…which goes with this, the contents of ~/bin/tmux:
#!/bin/bash
# If there are any sessions that aren't attached, attach to the first one
# Otherwise, start a new session
for line in $(tmux ls -F "#{session_name},#{session_attached}"); do
name=$(echo $line | cut -d ',' -f 1)
attached=$(echo $line | cut -d ',' -f 2)
if [ $attached -eq 0 ]; then
tmux attach -t $name
exit
fi
done
tmux -u
Basically, what happens is that whenever I start a terminal session, if I’m not already attached to a tmux session, I find a session that’s not already attached to and attach to it. If there aren't any, I create a new one.
This really tidies up my workflow and means that I never forget about any old sessions I’d detached.
Oh and one last thing, ctrl-a s is the best thing in tmux ever. It
shows a list of tmux sessions which can be expanded to show what’s
running in them and you can then interactively re-attach your terminal
to one of them. In short, I can start a terminal from any desktop or vt
and quickly attach to something that’s happening on any other. I use
this feature a lot.
Netcat
published 2014-04-15
I had occasion recently to need an entry in my ssh config such that connections to a certain host would be proxied through another connection. Several sources suggested the following snippet:
Host myserver.net
ProxyCommand nc -x <proxy host>:<proxy port> %h %p
In my situation, I wanted the connection to be proxied through an ssh tunnel that I already had set up in another part of the config. So my entry looked like:
Host myserver.net
ProxyCommand nc -x localhost:5123 %h %p
Try as I might however, I just could not get it to work, always receiving the following message:
Error: Couldn't resolve host "localhost:5123"
After some head scratching, checking and double-checking that I had set up the proxy tunnel correctly, I finally figured out that it was because I had GNU netcat installed rather than BSD netcat. Apparently, most of the people in the internet use BSD netcat :)
Worse, -x is a valid option in both netcats but does completely
different things depending on which you use; hence the
less-than-specific-but-technically-correct error message.
After that revelation, I thought it was worth capturing the commonalities and differences between the options taken by the netcats.
Common options
-h
Prints out nc help.
-i interval
Specifies a delay time interval between lines of text sent and received. Also causes a delay time between connections to multiple ports.
-l
Used to specify that nc should listen for an incoming connection rather than initiate a connection to a remote host. It is an error to use this option in conjunction with the -p, -s, or -z options. Additionally, any timeouts specified with the -w option are ignored.
-n
Do not do any DNS or service lookups on any specified addresses, hostnames or ports.
-p source_port
Specifies the source port nc should use, subject to privilege restrictions and availability.
-r
Specifies that source and/or destination ports should be chosen randomly instead of sequentially within a range or in the order that the system assigns them.
-s source
Specifies the IP of the interface which is used to send the packets. For UNIX-domain datagram sockets, specifies the local temporary socket file to create and use so that datagrams can be received. It is an error to use this option in conjunction with the -l option.
-tin BSD Netcat,-Tin GNU Netcat
Causes nc to send RFC 854 DON’T and WON’T responses to RFC 854 DO and WILL requests. This makes it possible to use nc to script telnet sessions.
-u
Use UDP instead of the default option of TCP. For UNIX-domain sockets, use a datagram socket instead of a stream socket. If a UNIX-domain socket is used, a temporary receiving socket is created in /tmp unless the -s flag is given.
-v
Have nc give more verbose output.
-w timeout
Connections which cannot be established or are idle timeout after timeout seconds. The -w flag has no effect on the -l option, i.e. nc will listen forever for a connection, with or without the -w flag. The default is no timeout.
-z
Specifies that nc should just scan for listening daemons, without sending any data to them. It is an error to use this option in conjunction with the -l option.
BSD netcat only
-4
Forces nc to use IPv4 addresses only.
-6
Forces nc to use IPv6 addresses only.
-b
Allow broadcast.
-C
Send CRLF as line-ending.
-D
Enable debugging on the socket.
-d
Do not attempt to read from stdin.
-I length
Specifies the size of the TCP receive buffer.
-k
Forces nc to stay listening for another connection after its current connection is completed. It is an error to use this option without the -l option.
-O length
Specifies the size of the TCP send buffer.
-P proxy_username
Specifies a username to present to a proxy server that requires authentication. If no username is specified then authentication will not be attempted. Proxy authentication is only supported for HTTP CONNECT proxies at present.
-q seconds
after EOF on stdin, wait the specified number of seconds and then quit. If seconds is negative, wait forever.
-S
Enables the RFC 2385 TCP MD5 signature option.
-T toskeyword
Change IPv4 TOS value. toskeyword may be one of critical, inetcontrol, lowcost, lowdelay, netcontrol, throughput, reliability, or one of the DiffServ Code Points: ef, af11 … af43, cs0 … cs7; or a number in either hex or decimal.
-U
Specifies to use UNIX-domain sockets.
-V rtable
Set the routing table to be used. The default is 0.
-X proxy_protocol
Requests that nc should use the specified protocol when talking to the proxy server. Supported protocols are "4" (SOCKS v.4), "5" (SOCKS v.5) and "connect" (HTTPS proxy). If the protocol is not specified, SOCKS version 5 is used.
-x proxy_address[:port]
Requests that nc should connect to destination using a proxy at proxy_address and port. If port is not specified, the well-known port for the proxy protocol is used (1080 for SOCKS, 3128 for HTTPS).
-Z
DCCP mode.
GNU netcat only
-c,--close
Close connection on EOF from stdin.
-e,--exec=PROGRAM
Program to exec after connect.
-g,--gateway=LIST
Source-routing hop point(s), up to 8.
-G,--pointer=NUM
Source-routing pointer: 4, 8, 12, …
-L,--tunnel=ADDRESS:PORT
Forward local port to remote address.
-o,--output=FILE
Output hexdump traffic to FILE (implies -x).
-t,--tcp
TCP mode (default).
-V,--version
Output version information and exit.
-x,--hexdump
Hexdump incoming and outgoing traffic.
Epilogue
I uninstalled GNU netcat and installed BSD netcat btw ;)
btw
published 2014-01-31
I discovered my new favourite fact about my new favourite language recently. I suppose it should be obvious but I hadn't though about it in explicitly these terms.
Given:
char* myStringArray[] = {"Hello", "Goodbye", "Tomatoes"};
int index = 2;
then the following will print Tomatoes:
printf("%s\n", myStringArray[index]);
and so (this is the bit I hadn't fully realised) will this:
printf("%s\n", index[myStringArray]);
Good times :)
Things we learned at the LUG meet
published 2013-05-10
- vimrc comments start with
" - howdoi would be useful if it worked
xargs -I {}is handy
Git aux
published 2013-02-11
For a while now, I’ve been wanting to keep various parts of my home directory in sync.
At first, I created a git repository for storing my dotfiles but I found it a pain to keep the repository up-to-date.
Fairly recently, someone pointed out git-annex to me. After a good read of the documentation, it sounded like it could be useful but probably more than I needed and perhaps not quite what I really wanted. Besides, I couldn’t get the bloody thing to install.
So I did what any geek would do, I wrote my own :D
See git-aux (or AUR if you’re on Arch Linux).
Basically, I wanted an easy to way to keep a git repository in sync with an directory external to it. With git aux installed, I get pretty much exactly what I wanted with a few simple commands.
After creating a new git repository, I do git aux init ~/ to tell
git-aux that I want it to sync this repo with my home directory.
I then do git aux add ~/.vimrc ~/.ssh/config ~/.bashrc and any other
files I want from my home directory. This copies those files into the
repository and I can then commit them in the usual way.
If I make changes in my home directory, I use git aux sync to update
the copies in the repository.
If I’ve made changes on another machine and want to apply those changes
from the repo to the home dir on this machine, I do git aux apply.
And that’s it :)
It’s unfinished and probably broken in places but mostly does what I was looking for.
Lost at C
published 2012-08-30
This week I've learned a few things (always the mark of a good week in my book), the foremost of which is that I don’t know very much about C.
I expect this post will mostly result in comments such as "well, duh…" and the like :)
How I spent an afternoon chasing a star...
After a fairly relaxing bank holiday weekend, I came back to work on Tuesday to find myself in the position of needing a to write a library for a client to plug into their software and to have it ready by Friday.
Though I’d written some (very bad) C++ while at uni, I've fairly recently written a couple of very small utilities in C (the library they use is written in C and I fancied a challenge) and wanted to learn some more, so I chose C as the language to write in.
This afternoon, with the library and a small demo application written, I handed the code over to my colleague who’d promised to do all the necessary wrapping up to take my developed-in-linux code and produce a windows DLL from it. After a short while, he’d compiled the library and the demo, BUT… the demo app crashed every time.
At first, it looked like I’d forgotten to free() some malloc()ed memory. I had; but even after doing so, the code was still crashing in windows. The search continued for quite some time until I eventually found what was wrong.
There was an asterisk where there shouldn't have been, FFS!
It turns out that I’d carried some pre-conceptions with me from my previous life as a Java developer and various other places. I’m so used to pretty much every language passing things around by value when the data is small (ints, chars, etc.) and by reference when it’s not (objects, etc.). I was completely unprepared for the fact that C deals only in values.
I’m not one of those who are scared of pointers, I’m quite comfortable with pointer arithmetic, allocating and freeing memory and the like. What I had was some code like this:
typedef struct {
int a;
int b;
} AB;
void do_some_stuff(int *a, int *b, int num_records, AB **out) {
int i;
AB ab[num_records];
for(i=0; i<num_records; i++) {
ab[i].a = a[i];
ab[i].b = b[i];
}
*out = ab;
}
void get_stuff() {
int a[2] = {1, 2};
int b[2] = {3, 4};
AB *ab;
do_some_stuff(a, b, 2, &ab);
// Do some stuff with ab;
}
Although the real code actually did useful things :P
After handing the code over however, it transpired that MSVC doesn't
support all of C99 (why pick a standard and implement part of it?!)
specifically, variable-length arrays; so the AB ab[num_records] line
had to go.
Here’s where my preconception came in:
So that array declaration became
AB *ab = malloc(sizeof(AB*) * num_records) and a corresponding
free(ab) in get_stuff().
Yep, nothing in C is a reference unless you really, really say it is.
Arrays of structs are just like arrays of any other type: a sequence of
those things laid end to end in memory. sizeof(AB*) needed to be
sizeof(AB) and that was it.
The. Entire. Afternoon.
Consider that my lesson learned.
Luckily, I seem to have ended up quite fond of C, pleasantly more aware of how it works, and quite keen to write some more.
Ire
published 2012-07-07
Call me crazy (thanks) but I like regular expressions.
I like them enough to have decided that what I really needed was a tool that let me put regular expressions in my regular expressions (yo dawg). I had the idea for this a while ago but only got around to realising it a few days ago.
The basic idea is a scripting language for matching text via regular expressions, and then applying further regular expressions (and replacements) dependent on those.
I wanted to keep the syntax fairly free so there’s support for representing blocks by indentation or within braces. To avoiding ambiguity, indenting can’t be used inside braces although the opposite is fine.
Within braces, expressions should be separated by semi-colons.
I also wanted support for creating named blocks of code (functions if you like) and for flexibility over the character used to delimit the parts of an expression.
Example
After some mucking about, what I've ended up with is summat that looks like this:
>proc
/^(.+)\s+@/Model: $1\n/pt
/@\s+(.+)\n$/Speed: $2\n/pt
/^processor\s+:\s+(\d+)/# CPU $1\n/p
/^model name\s+:\s+//
<proc>
//\n/p
The idea being that you pipe /proc/cpuinfo through that and you get a
summary that looks like:
# CPU 0
Model: Intel(R) Core(TM) i5-2467M CPU
Speed: 1.60GHz
# CPU 1
Model: Intel(R) Core(TM) i5-2467M CPU
Speed: 1.60GHz
# CPU 2
Model: Intel(R) Core(TM) i5-2467M CPU
Speed: 1.60GHz
# CPU 3
Model: Intel(R) Core(TM) i5-2467M CPU
Speed: 1.60GHz
Breaking it down
>proc
/^(.+)\s+@/Model: $1\n/pt
/@\s+(.+)\n$/Speed: $1\n/pt
Define a block called proc and do not execute it yet.
The first line of proc matches a string followed by a space and an @
symbol. It then replaces what it’s found with Model: (the string at the
beginning). Then it prints the result (the p flag) and discards the
replacement that has taken place (temporary apply - the t flag).
The second line does similar but looks for the @ followed by a space, a string, and a newline then prints "Speed: (the string)".
/^processor\s+:\s+(\d+)/# CPU $1\n/p
Match a line starting with processor and print out "CPU (the number)"
/^model name\s+:\s+//
<proc>
//\n/p
Match a line starting with Model name, and remove everything up until
the start of the data. Then call the block called proc. Finally, print
a newline character.
Obviously this is a fairly contrived example ;)
Trying it out
Like most things these days, I wrote the engine for Ire in node.js.
If you have that installed, you can install ire with:
npm install -g ire
or if you’re feeling less brave or more paranoid, just npm install ire
to install it to the current folder.
Further details are in the README.
Final word
Yes, I am fully aware that this is somewhat limited in use and probably completely pointless.
I’m sure someone will point out that I could do the kinds of things I want with pure sed or awk or somesuch. To those people: "you’re missing the point". See my geekcode for details :P
Break In!
published 2011-10-27
A while ago, I decided to learn how to use the canvas and that for my first project I was going to write a breakout clone. Pretty standard fare for a first-time project :)
After writing some routines to draw blocks on the screen some weeks ago, I finally got around to doing some real work on it this evening. Two or three hours later, I'd ended up with a mostly working, radial version of Breakout.

Update 2024: I am no longer hosting this anywhere, so you can't play it. I might see if I can find it and host it again.
There are still some obvious bugs (the collision detection is a bit shoddy) and it doesn't keep score or do anything special when you win but it's reasonably fun and I'm quite pleased with what I've achieved in just a couple of hours.
The code is released under the
If-You-Steal-This-Without-Asking-Me-I'll-Bite-Your-Legs-Off licence ;)
xmodmap Hints and Tips
published 2011-10-22
Originally posted on Rolling Release. I'm reposting this here as I recently broke my finger and so made a few changes to my xmodmap settings to accommodate the ensuing one-handed typing. Once again, I had to search for how to use xmodmap and came upon my own post. I'm keeping it here for easier reference and in the hope the details will burn deeper into my mind. It was written for a tutorial column so excuse the tone.
About xmodmap
Xmodmap is used to control the mappings between the keys you press on the keyboard and the results you will experience on screen. Some common usage examples of xmodmap are:
- Disabling and/or reallocating the caps-lock key
- Mapping certain foreign or other special characters to keys on your keyboard
- Enabling "media" keys
- Terminology
To achieve things like the above, you'll be mapping KeyCodes to KeySyms and KeySyms to Modifiers so it's obviously important to understand exactly what xmodmap means by these terms (I certainly didn't when I started out).
KeyCode
A KeyCode is a number generated by your keyboard when you press a certain key. For example, the space bar usually produces the KeyCode 128.
KeySym
A KeySym is simply a word used to name a type of key. This concept is very important because it means that applications don't need to interpret the information output by your keyboard directly; they can refer to keys by name.
As mentioned above, most keyboards produce the code 128 when you press the spacebar but it would be possible to have a very non-standard keyboard that outputs the KeyCode 64 when the spacebar is pressed. You'd certainly want to ensure that code 64 is interpreted as a spacebar press without having to rewrite all the applications you use. To do this, we'd map the KeyCode 64 to the KeySym "space".
Modifier
A Modifier is a special kind of key that can be held at the same time as another key and modify its output. For example, when you press the A key on your keyboard, you see the letter 'a' appear on screen. If you hold shift and press A, you'll see the letter 'A' – shift is a Modifier.
Let's start with looking at modifiers to get the hang of Modifiers and KeySyms...
Modifiers
There are 8 modifiers:
- Shift
- Lock
- Control
- Mod1
- Mod2
- Mod3
- Mod4
- Mod5
Xmodmap provides three different operations for changing the way KeySyms are mapped to Modifiers: clear, add, and remove.
My favourite example – turning off caps lock:
$ xmodmap -e "clear Lock"
This command clears the Lock modifier meaning that no keys now produce a caps lock effect. Bliss!
To reassign the caps lock key to do something more useful:
$ xmodmap -e "add Shift = Caps_Lock"
This adds the KeySym "Caps_Lock" to the list of keys that produce the Shift modifier. In other words, we've turned caps lock into another shift key.
If you change your mind and want to stop the caps lock key behaving as a shift key:
$ xmodmap -e "remove Shift = Caps_Lock"
This is basically the opposite of the previous example.
Mapping KeyCodes to KeySyms
Now we've got the hang of changing the Modifiers, we'll round off by looking at mapping the physical keys on your keyboard to produce the results you want.
First things first, you'll need to know the keycode of the key you want to change. To do this, you can use xev.
$ xev
After running xev, press the key in question and you'll see some output like this in your terminal:
KeyPress event, serial 21, synthetic YES, window 0x800001,
root 0x40, subw 0x0, time 1539131, (69,8), root:(683,402),
state 0x0, keycode 63 (keysym 0xfe03, ISO_Level3_Shift), same_screen YES,
XLookupString gives 0 bytes:
XmbLookupString gives 0 bytes:
XFilterEvent returns: False
The third line is the one we're interested in. You'll see the word keycode followed by the number you're going to need next, in the example above it's 63.
Now we're going to map that key to give us some foreign characters.
$ xmodmap -e "keycode 63 = e E eacute Eacute"
The "keycode" command maps a KeyCode to a number of KeySyms. The order of the KeySyms is important as it represents how the KeySyms are derived.
- The key pressed alone
- With the Shift modifier
- The key pressed along with the Mode_switch key
- With Mode_switch AND Shift
Mode_switch is just another keysym and you can map it to a chosen key on your keyboard like this:
$ xmodmap -e "keycode 64 = Mode_switch"
My personal choice is to map Mode_switch to my AltGr key. To do this, you can use a special version of the keycode command. `xmodmap -e "keycode Alt_R = Mode_switch"` This asks xmodmap to lookup what keycode(s) are currently assigned to the KeySym Alt_R (right alt) and assign them to Mode_switch as well.
So with the above mappings, here's what happens when I press the keys on my keyboard:
- The key on it's own -> A lowercase 'e'
- With shift -> An uppercase 'E'
- With AltGr -> A lowercase e-acute (as used in French for example)
- With AltGr and shift -> An uppercase E-acute
Saving Your Mappings
Once you've decided how you'd like everything set up, you obviously
don't want to have to type all those xmodmap lines in every time you
start X. To save you from this, you can just put all your mapping into a
file (I save mine at ~/.xmodmap) and then just tell xmodmap to load
from it.
$ xmodmap ~/.xmodmap
Ideally, you'd add that line to your .xinitrc so it runs automatically
when you start X.
The End
That just about wraps up this howto. I hope somebody finds it useful as I certainly found xmodmap confusing in my early days. Now I have my keyboard customised to do just what I want and I couldn't live without it.
Useful Links
A few useful links about xmodmap.